Current research topics
Randomized risk estimation
In high-dimensional machine learning, tremendous amounts of computational time are spent on hyperparameter tuning, which requires an estimate of the risk of a model. In high-dimensional regimes, it is undesirable to set aside data for validation that could be used for training; instead, we obtain a variance-reduced estimate of risk through cross-validation. However, this requires training the model multiple times, which can really add up. Not to mention that in high dimensions, standard K-fold cross-validation is biased, which can only be eliminated by increasing the number of folds at a cost of even more training time.

We introduce a new randomized risk estimation method called RandALO. RandALO is a randomized approximation to approximate leave-one-out cross-validation (ALO-CV), which for virtually arbitrary convex losses and regularization penalties requires only the solving of a simple quadratic program. As a result, it is very fast to compute and can even outperform K-fold cross-validation with highly optimized implementations of methods like the Lasso, in both statistical risk estimation and wall clock time.
Adaptivity in neural networks
Neural networks are seemingly universal learning machines that excel at any task for which we have enough data. In contrast, linear or kernel models, although much more theoretically understood, suffer significantly in cases of model misspecification, which more data cannot alleviate. How are neural networks able to learn structure from data, even if the model is misspecified? At the same time, what is the value of good implicit biases in the architecture of a neural network?
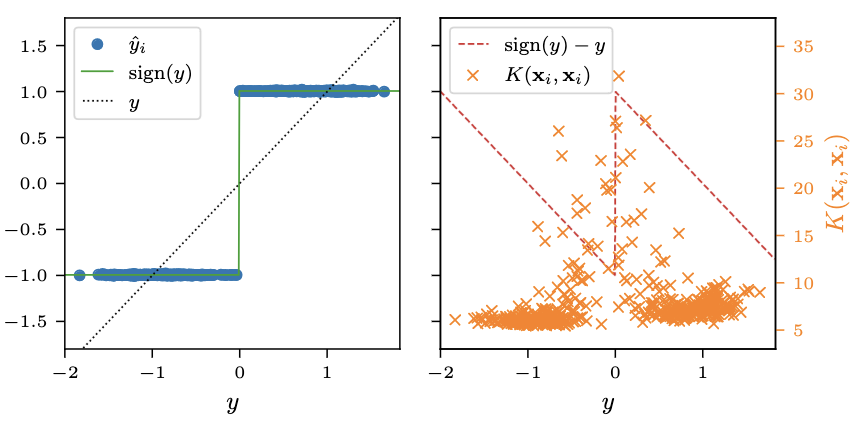
One hypothesis is that the implicit bias of a neural network is captured in the feature space of the neural tangent kernel. However, this kernel only precisely captures the behavior of a neural network in certain unrealistic settings, and actual neural networks have feature spaces which change throughout training, which allows them to better leverage structure in data. In our work, we consider a generic learning setting in which the feature space is allowed to change throughout training and show that this results in structure-inducing regularization of the model. In a neural network context, this corresponds to an approximate low rank penalty on the weight matrices, which explains the success of low rank fine tuning techniques like LoRA.
Asymptotics of sketching
Sketching or random projections are commonly used tools to reduce computational and memory requirements of data processing algorithms. The idea is that if the random projection is chosen sufficiently, the projection preserves all meaningful structure in the data such that there is no loss in performance. Classically, most guarantees for sketching state that as long as the sketched dimension is roughly as large as the intrinsic dimension of the data, then any algorithm using the sketched data will recover the same solution as if the original unsketched data were used.
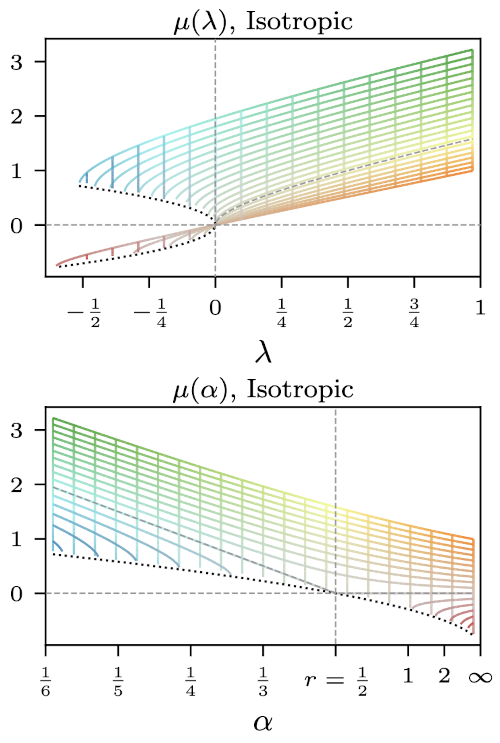
However, in many settings, either the intrinsic dimension is unknown, or other constratings limit us to using smaller dimensions. In this regime, classical results provide no insight into the solutions of sketched algorithms; instead, the resulting solutions are often quite far from the unsketched solution. We consider the particular setting of matrix inversion, as used in least squares (ridge) regression, and using asymptotic random matrix theory, we show that taking the regularized pseudoinverse of a sketched matrix is asymptotically equivalent to taking the inverse of the original matrix at a different regularization level.
This result is not unique to i.i.d. type sketches commonly studied in random matrix theory. In fact, we show that the same type of result holds for any sketch that is free from the data, a notion from free probability theory. Furthermore, the effective regulatization level is a function of the spectral distribution of the sketch itself, and we can characterize effect of the choice of a particular type of sketch.
Risks under covariate shifts
It is most often the case that we train models on a training dataset from a particular distribution, and then we apply the model in production to data that typically comes from a similar but different distribution. As such, there is an important question that is raised: even if the machine learning task remains the same (that is, the conditional distribution of the labels given data is unchanged), can we rely on in-distribution validation error to reliably perform model selection for models that are applied to out-of-distribution data?
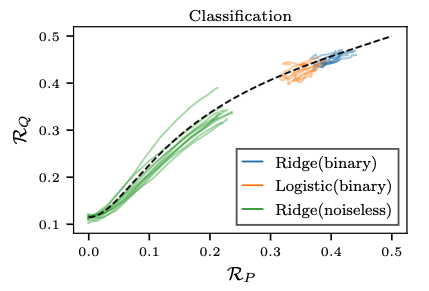
An interesting recent line of empirical work suggests that for "natural" distribution shifts, the answer is affirmative, in the sense that there is a monotonic (often linear) relationship between the in-distribution and out-of-distribution generalization error, for a wide variety of model types and sample sizes. This raises the very interesting theoretical question: when should we expect monotonic risk relations between risks for broad classes of machine learning models?
We answer this question for the general class of linear models fit by empirical risk minimization with convex loss and ridge penalty. Remarkably, given certain necessary and sufficient conditions on covariate shift, there exists a monotonic risk relation that depends in no way on loss function, sample size, or regularization strength, and can thus be considered universal. However, the risk relations do depend critically on the risk metric itself, with squared error and misclassification error having drastically different monotonic relations, and some risk metrics like logistic loss and hinge loss having no monotonic relation at all.
Adaptive dropout and sparsity
There is a strong connection between ensemble methods and the dropout technique used in deep learning. As we point out, dropout can be viewed as an ensemble where the weights are shared across models. Thus, we can gain some insight into the behavior of ensembles by analyzing dropout, which is much easier to manipulate mathematically. For example, it has been known almost since dropout was proposed that dropout is equivalent to ridge regularization.
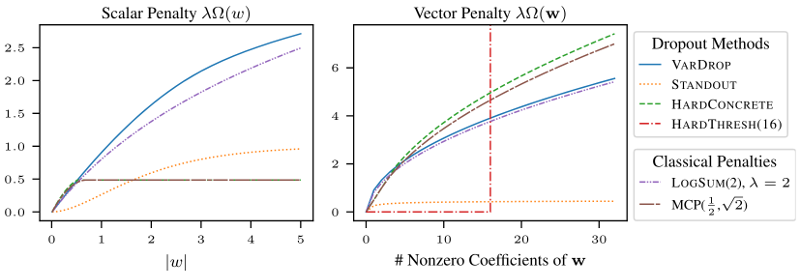
The question that this connection helps us to answer is: what happens when we use an adaptive ensemble/dropout algorithm? Interestingly, many state-of-the-art sparsification methods for deep learning can be cast as adaptive dropout algorithms. What's more, we prove a duality between adaptive dropout methods and subquadratic regularization, implying that any adaptive dropout strategy that samples features with higher weights more often results in sparse solutions. Furthermore, these state-of-the-art sparsity methods correspond nearly to sensible classical sparsity-inducing penalty choices.
Publications
preprints
-
P. T. Nobel, D. LeJeune, E. J. Candès,
“RandALO: Out-of-sample risk estimation in no time flat,” 2024, Submitted to JMLR.


2025
-
M. Dereziński, D. LeJeune, D. Needell, E. Rebrova,
“Fine-grained analysis and faster algorithms for iteratively solving linear systems,” 2025, Accepted to JMLR.
2024
-
Y. Dar, D. LeJeune, R. G. Baraniuk,
“The common intuition to transfer learning can win or lose: Case studies for linear regression,” 2024, SIMODS.
SIMODS
-
D. LeJeune, J. Liu, R. Heckel,
“Monotonic risk relationships under distribution shifts for regularized risk minimization,” 2024, JMLR.
 JMLR
JMLR
-
P. Patil, D. LeJeune,
“Asymptotically free sketched ridge ensembles: Risks, cross-validation, and tuning,” 2024, ICLR.
OpenReview
-
S. Alemohammad, J. Casco-Rodriguez, L. Luzi, A. I. Humayun, H. Babaei, D. LeJeune, A. Siahkoohi, R. G. Baraniuk,
“Self-consuming generative models go MAD,” 2023, ICLR.
OpenReview
-
D. LeJeune, P. Patil, H. Javadi, R. G. Baraniuk, R. J. Tibshirani,
“Asymptotics of the sketched pseudoinverse,” 2024, SIMODS.
 SIMODS
SIMODS
-
D. LeJeune, S. Alemohammad,
“An adaptive tangent feature perspective of neural networks,” 2024, CPAL.
OpenReview
-
L. Luzi, D. LeJeune, A. Siahkoohi, S. Alemohammad, V. Saragadam, H. Babaei, N. Liu, Z. Wang, R. G. Baraniuk,
“TITAN: Bringing the deep image prior to implicit representations,” 2024, ICASSP.
IEEE Xplore
2023
-
P. K. Kota, H. Vu, D. LeJeune, M. Han, S. Syed, R. G. Baraniuk, R. A. Drezek,
“Expanded multiplexing on sensor-constrained microfluidic partitioning systems,” 2023, Analytical Chemistry.
 ACS
ACS
-
V. Saragadam, D. LeJeune, J. Tan, G. Balakrishnan, A. Veeraraghavan, R. G. Baraniuk,
“WIRE: Wavelet implicit neural representations,” 2023, CVPR.
 Website
CVF
Website
CVF
-
J. Tan, D. LeJeune, B. Mason, H. Javadi, R. G. Baraniuk,
“A blessing of dimensionality in membership inference through regularization,” 2023, AISTATS.
PMLR
2022
- D. LeJeune, “Ridge regularization by randomization in linear ensembles,” 2022, Ph.D. thesis. Rice Research Repository
-
D. LeJeune, J. Liu, R. Heckel,
“Monotonic risk relationships under distribution shifts for regularized risk minimization,” 2022, ICML PODS Workshop.
-
P. K. Kota, D. LeJeune, R. A. Drezek, R. G. Baraniuk,
“Extreme compressed sensing of Poisson rates from multiple measurements,” 2022, IEEE Transactions on Signal Processing.
IEEE Xplore
2021
-
D. LeJeune, H. Javadi, R. G. Baraniuk,
“The flip side of the reweighted coin: Duality of adaptive dropout and regularization,” 2021, NeurIPS.
 NeurIPS
NeurIPS
-
S. Alemohammad, H. Babaei, R. Balestriero, M. Y. Cheung, A. I. Humayun, D. LeJeune, N. Liu, L. Luzi, J. Tan, R. G. Baraniuk,
“Wearing a MASK: Compressed representations of variable-length sequences using recurrent neural tangent kernels,” 2021, ICASSP.
IEEE Xplore
-
T. Yao, D. LeJeune, H. Javadi, R. G. Baraniuk, G. I. Allen,
“Minipatch learning as implicit ridge-like regularization,” 2021, IEEE BigComp.
IEEE Xplore
2020
-
D. LeJeune, H. Javadi, R. G. Baraniuk,
“The implicit regularization of ordinary least squares ensembles,” 2020, AISTATS.
PMLR
-
D. LeJeune, G. Dasarathy, R. G. Baraniuk,
“Thresholding graph bandits with GrAPL,” 2020, AISTATS.
PMLR
2019
-
D. LeJeune, R. Heckel, R. G. Baraniuk,
“Adaptive estimation for approximate k-nearest-neighbor computations,” 2019, AISTATS.
PMLR
-
D. LeJeune, R. Balestriero, H. Javadi, R. G. Baraniuk,
“Implicit rugosity regularization via data augmentation,” 2019.